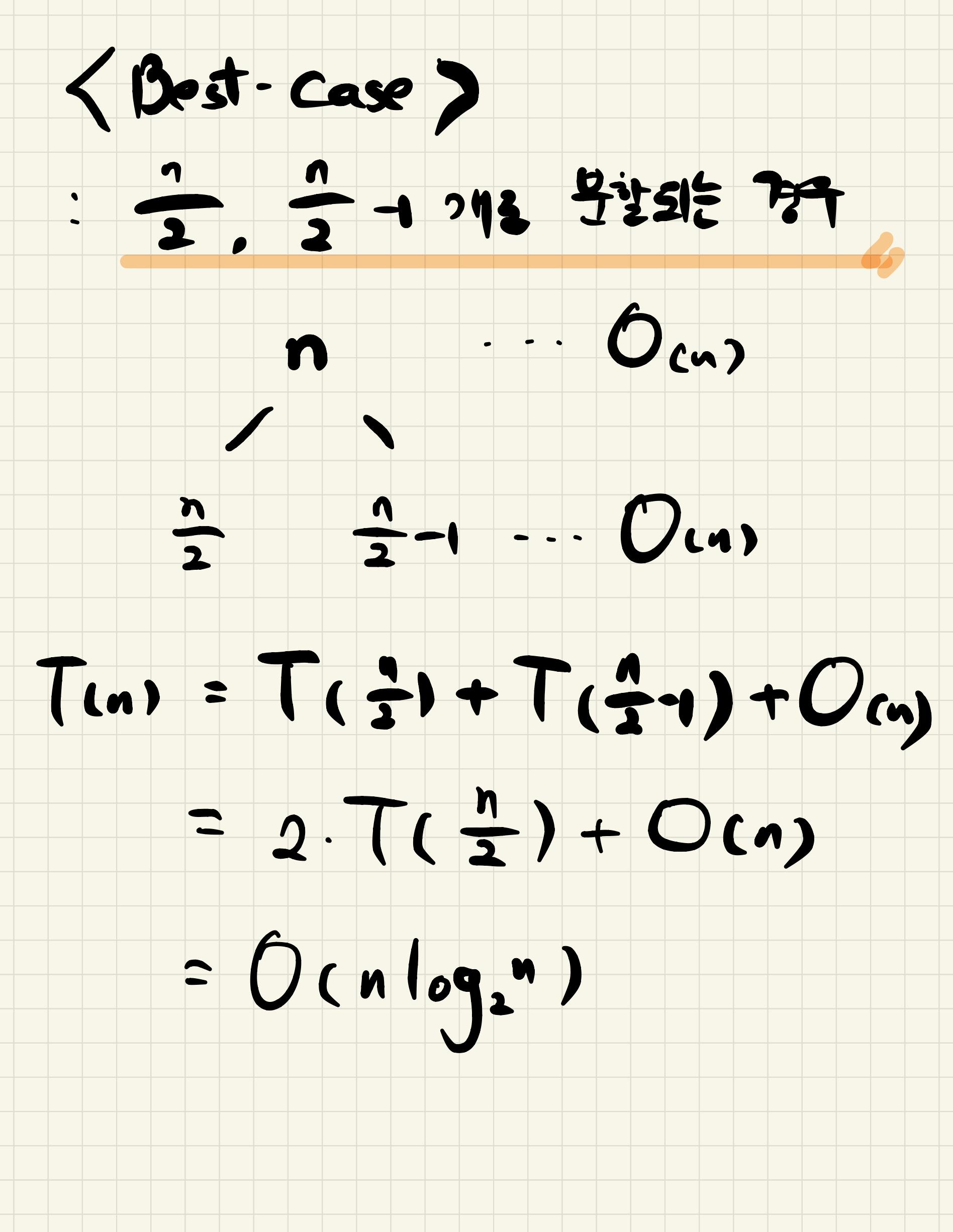jayyhkwon의 개발공부로그
jayyhkwon의 개발공부로그
비교정렬의 하한
16 Dec 2019 | Algorithm비교정렬의 하한
비교 정렬
- 비교정렬 이란 입력 원소들끼리 비교하여 정렬하는 방식을 말한다.
- 비교정렬 알고리즘의 예로는 퀵 정렬, 병합정렬, 힙 정렬 등등이 있다.
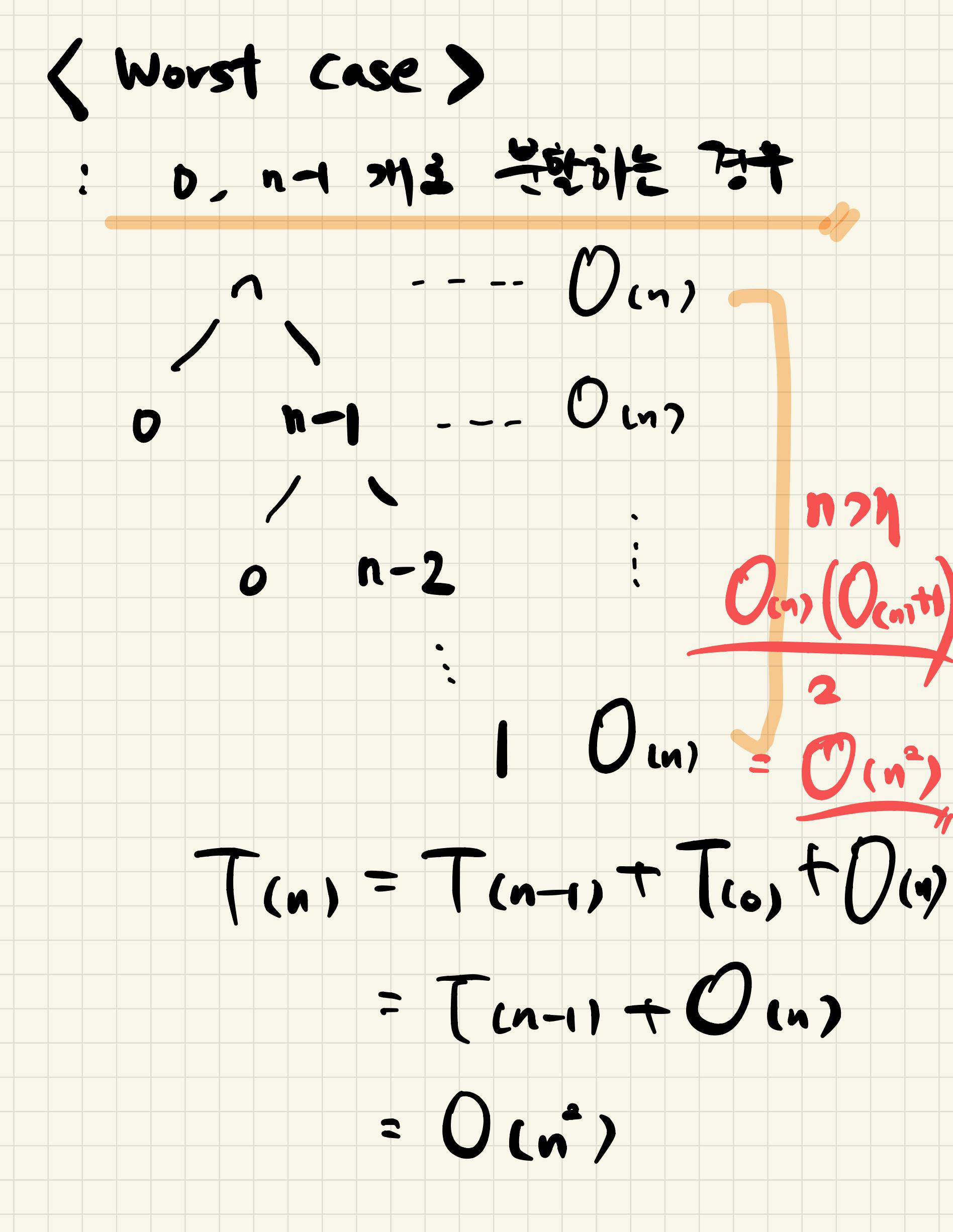
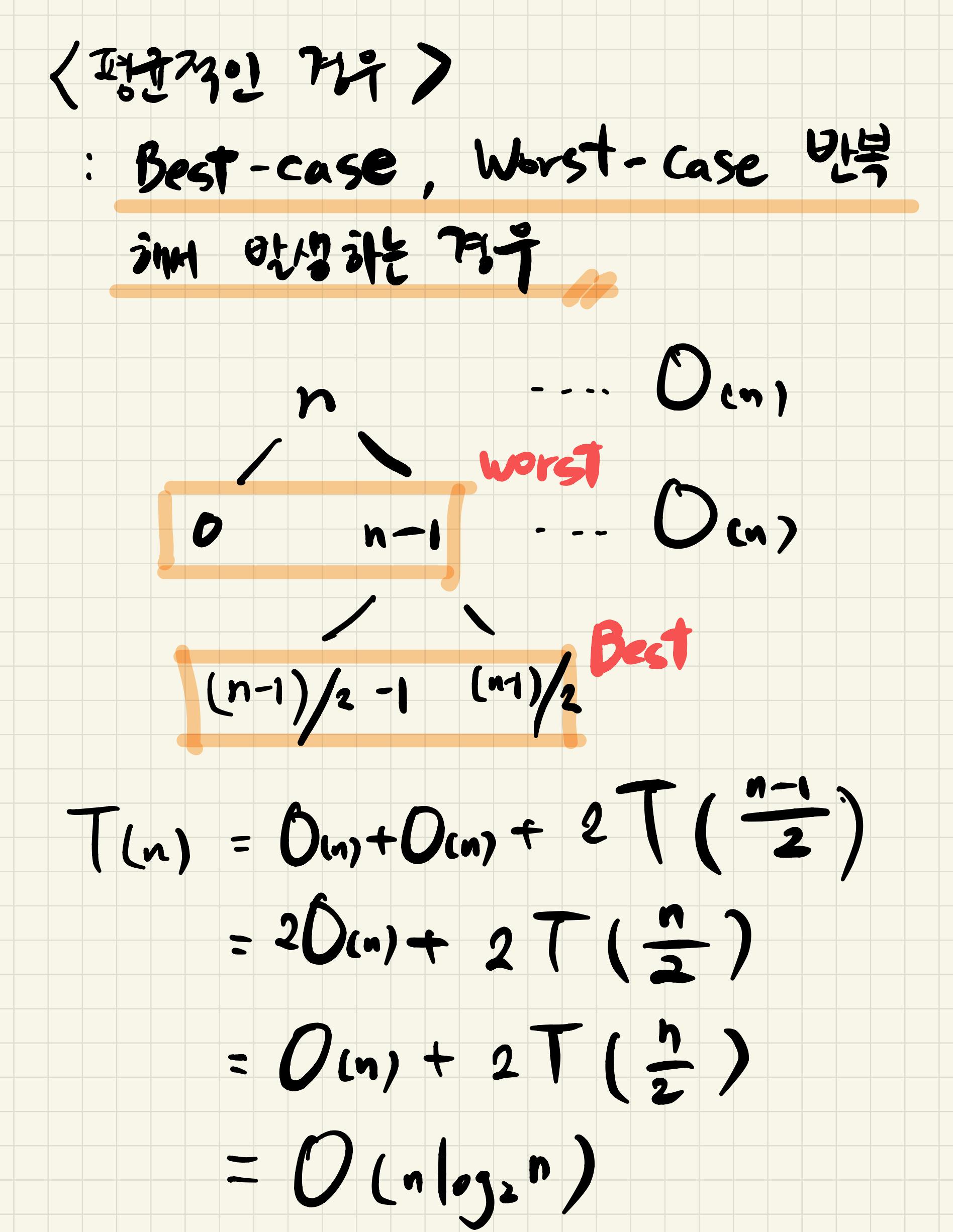
- 어떤 비교정렬 알고리즘을 사용하더라도 원소 n개를 정렬할 때
최악의 경우 비교를 Ω(nlogn) 번 해야하는 데 이를 비교정렬의 하한이라고 한다.
증명
-
다음과 같은 사진의 결정트리가 있다고 하자.
- 숫자 1,2,3은 원소 a1,a2,a3를 의미하고 a1=6, a2=8, a3=5라고 가정한다.
- 최종 결정된 <3,1,2>는 a3<=a1<=a2를 의미한다.

-
결정트리는 이진트리로 구성되어 있으며 리프(순열)의 갯수는 n!이다
이진 트리에서 리프의 갯수는 2^h를 넘을 수 없으므로 n! <= 2^h 양변에 이진로그를 취하면 h>=log(n!) h=Ω(nlogn)해당 링크를 참고하면 log(n!) = Ω(nlogn) 임을 알 수 있다.