18 Dec 2019
|
Algorithm
버킷 정렬
버킷 정렬
- 버킷정렬에서는 [0,1) 범위에서 원소를 균일하게 분포시키도록 하는 무작위 과정을 통해 입력이 균일하고 독립적으로 만들어 졌다고 가정한다.
- 평균 O(n)의 시간복잡도를 가진다.
- 정렬을 위해 추가 공간이 필요하다.
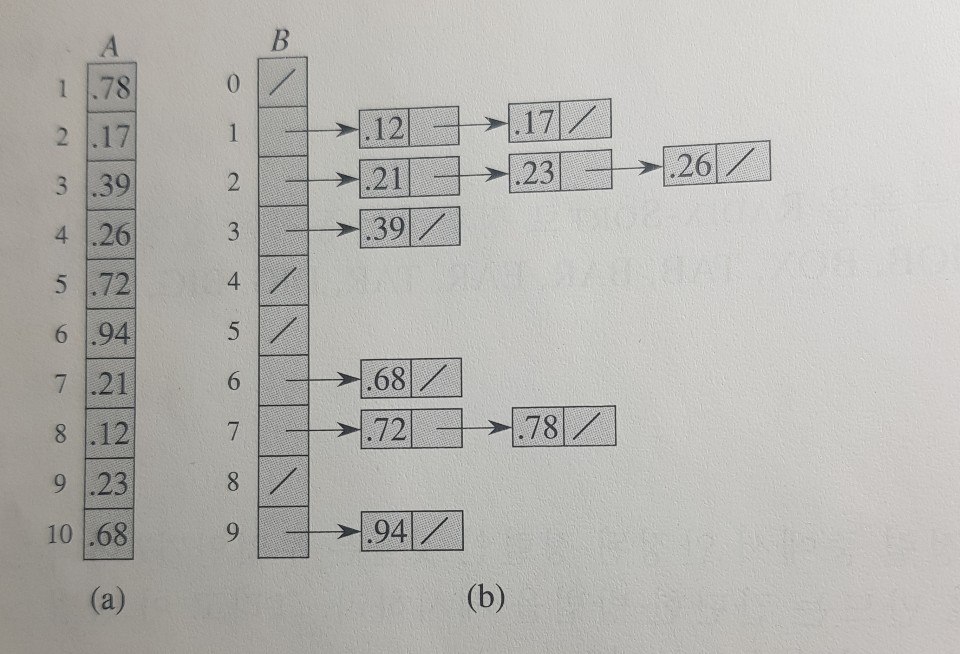
//pseudocode
BucketSort(A){
n=A.length;
//B[0..n-1]를 새로운 배열이라 하자
for(i=0 to n-1)
B[i]를 빈 리스트로 만든다.
for(i=1 to n)
A[i]를 리스트 B[nA[i]]에 삽입한다.
for(i=0 to n-1)
B[i]를 삽입 정렬을 사용해 정렬한다.(다른정렬 사용해도 된다)
리스트 B[0],B[1]...B[n-1]를 순서대로 연결한다.
}
Java로 버킷정렬 구현
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class BucketSortTest {
private double[] input;
private double[] output;
@BeforeEach
public void setUp(){
input = new double[]{0.78,0.17,0.39,0.26,0.72,0.94,0.21,0.12,0.23,0.68};
output = new double[]{0.12,0.17,0.21,0.23,0.26,0.39,0.68,0.72,0.78,0.94};
}
@Test
public void test(){
double[] result = BucketSort.sort(input);
assertArrayEquals(result,output);
}
}
import java.util.*;
public class BucketSort {
public static double[] sort(double[] src){
double[] result = new double[src.length];
int resultIdx = 0; // 버킷 별로 정렬된 원소를 result 배열에 넣을 때 필요한 idx
// [List<Double>,List<Double>,List<Double>...] 배열을 만든다(버킷)
List<Double>[] buckets = new ArrayList[10];
for(int i=0; i<src.length; i++){
int idx = (int) ((src[i]*src.length)%10);
if(buckets[idx] == null){
buckets[idx] = new ArrayList<>();
}
buckets[idx].add(src[i]);
}
for(int i=0; i<buckets.length; i++){
// 버킷별로 삽입정렬로 정렬한다
InsertionSort(buckets[i]);
List<Double> sorted = buckets[i];
if(sorted == null)
continue;
// 버킷별로 정렬한 원소를 result 배열에 담는다
for(int j=0; j<sorted.size(); j++){
result[resultIdx++] = sorted.get(j);
}
}
return result;
}
private static void InsertionSort(List<Double> src){
if(src == null)
return;
for (int i = 1; i < src.size(); i++) {
double key = src.get(i);
int j = i - 1;
while (j >= 0 && src.get(j) > key) {
src.set(j+1,src.get(j));
j--;
}
src.set(j + 1, key);
}
}
}
ref. Introduction to Algorithms
17 Dec 2019
|
Network
##IP/이더넷 송수신 과정(1)
패킷의 기본
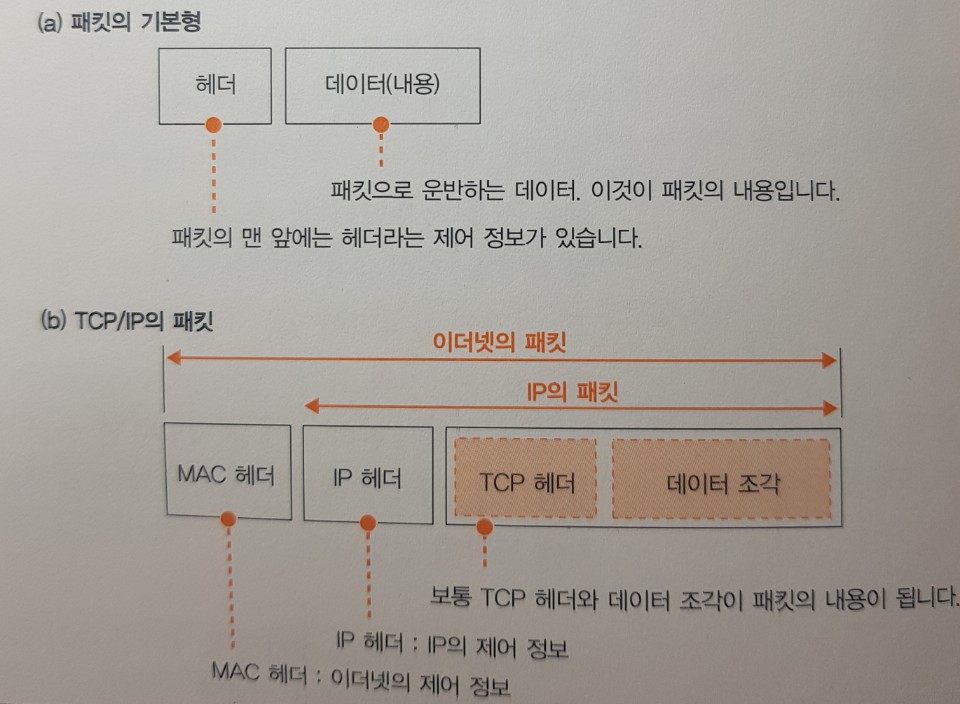
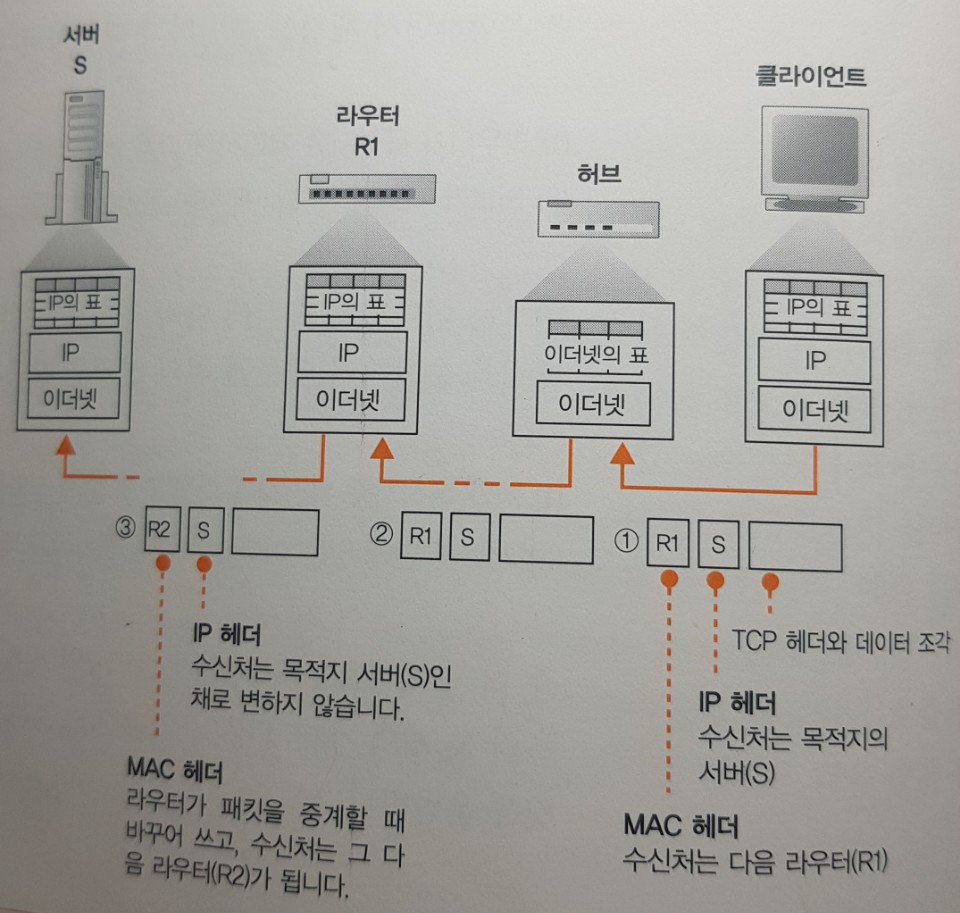
패킷 송∙수신 동작의 개요
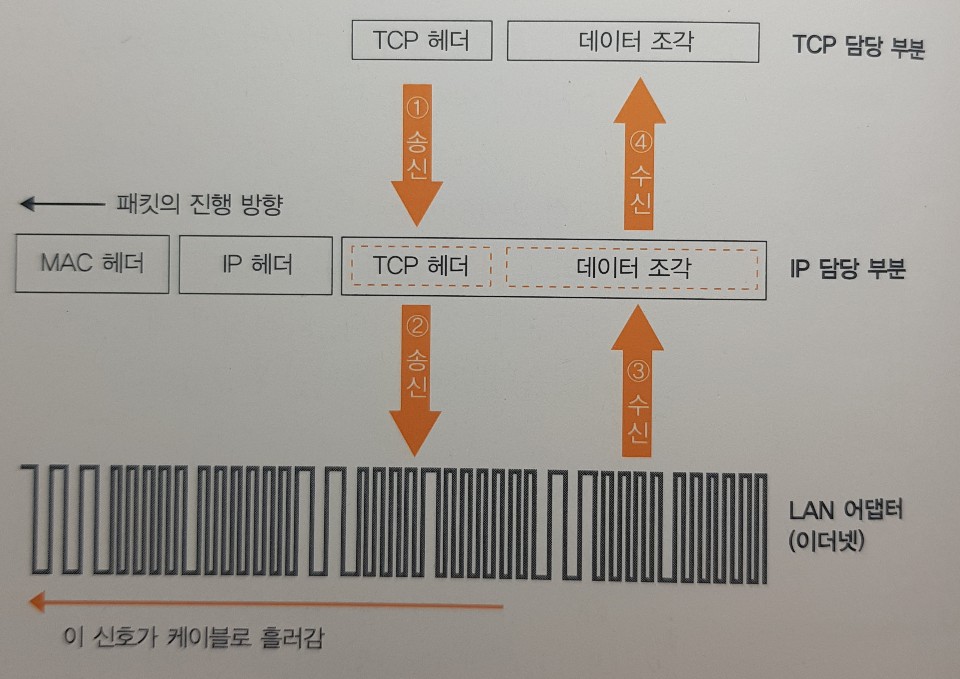
-
IP 담당 부분은 패킷을 운반하는 동작 전체에서 입구 부분에 불과하다.
먼저 TCP 담당 부분이 IP 담당 부분에 패킷 송신을 의뢰하는 것부터 시작된다.
의뢰 동작을 할 때 TCP 담당 부분은 데이터의 조각에 TCP 헤더를 부가한 것을 IP 담당 부분에게 건내준다. 이 것이 패킷에 들어가는 내용물이 되고, 이와 동시에 통신상대의 IP주소를 나타낸다.
IP 담당 부분은 내용물을 한 덩어리의 디지털 데이터로 간주하고, 그 앞에 제어 정보를 기록한 헤더를 부가한다. 이 헤더가 IP 헤더와 MAC 헤더라는 2개의 헤더이다.
이렇게 만든 패킷을 네트워크용 하드웨어에 건네준다. 하드웨어는 이더넷이나 무선 LAN 등을 말한다. (여기서부터 LAN 어댑터로 통일) LAN 어댑터로 전달할 때 패킷의 모습은 0과 1로 이루어진 디지털 데이터이다. 이것이 LAN 어댑터에 의해 전기나 빛의 신호 상태로 바뀌어 케이블에 송출된다.
응답이 돌아오면 마찬가지로 전기나 빛의 신호 상태로 돌아올 것이고 이 것을 LAN 어댑터에서 디지털 데이터의 모습으로 되돌린다. 그러면 IP 담당 부분이 MAC 헤더와 IP 헤더 뒤에 이어지는 내용물, TCP 헤더와 데이터 조각을 TCP 담당 부분에게 건네준다.
수신처 IP 주소를 기록한 IP 헤더를 만든다
-
IP 담당 부분은 TCP 담당 부분에서 패킷 송∙수신 의뢰를 받으면 IP 헤더를 만들어 TCP 헤더의 앞에 붙인다. IP 헤더에서 가장 중요한 것은 수신처 IP와 송신처 IP이다. 수신처 IP 주소는
애플리케이션->TCP 담당부분->IP로 전달받은 주소이며, IP는 패킷을 송신할 책임만 가지므로 IP주소가 잘못된 경우 애플리케이션측에 책임이 있는 것으로 간주한다.
송신용 IP주소는 LAN 어댑터당 하나씩 할당되므로 LAN 어댑터가 여러개일 경우 하나를 선택해야한다.
-
프로토콜 번호라는 필드에도 값을 설정한다. 프로토콜 번호란 패킷에 들어간 내용물이 어디에서 의뢰받은 것인지를 나타내는 값이다. TCP에서 받은 의뢰받은 값이라면 06(16진수), UDP에서 의뢰받은 값이라면 17(16진수)로 표기한다.


- 이 IP용 표를 경로표라 부른다.
- Network Destination : 수신처 IP 주소와 비교하여 어느 행에 해당하는지 찾아낸다
- Interface : LAN 어댑터 등의 네트워크용 인터페이스를 나타내고, 인터페이스에서 패킷을 송신하면 상대에 패킷을 전해줄 수 있다는 의미이다.
-
Gateway : 다음 라우터의 IP 주소
- 만약 라우터를 나타내는 ‘Gateway’ 항목과 ‘Interface’ 항목의 IP 주소가 같으면 라우터로 중계하지 않고 상대에게 직접 패킷을 전할 수 있는 것이 된다.
이더넷용 MAC 헤더를 만든다
- IP 헤더를 만들었으면 IP 담당 부분 앞에 MAC 헤더를 붙인다. 이더넷의 수신처 판단구조로 사용하는 것이 MAC 헤더이다.
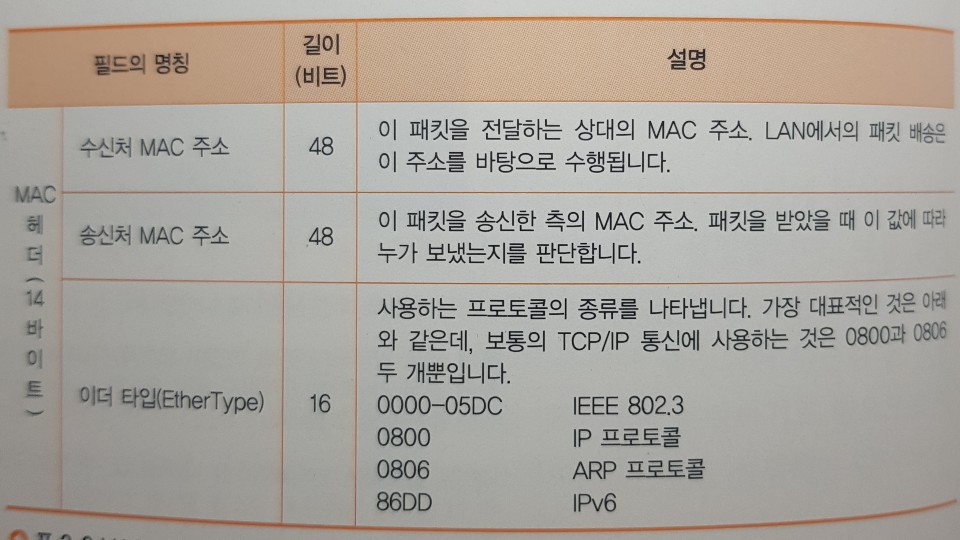
MAC 헤더는 수신처 MAC주소, 송신처 MAC주소, 이더타입 세 가지 항목으로 나뉜다.
IP주소는 32비트이지만 MAC주소는 48비트이며, IP주소는 ‘무슨 동 몇 번지’와 같이 그룹화 개념이지만 , MAC주소에는 이러한 개념이 없고 48비트 한 개의 값으로 받아들여진다.
이더타입은 프로토콜 번호가 비슷하다. MAC 헤더를 제외한 패킷의 내용물이 무엇인지를 이더타입으로 나타낸다. IP나 ARP라는 프로토콜의 소켓이며 가각에 대응하는 값이 규칙을 정해져 있으므로 규칙에 따라 값을 기록한다.
송신처 MAC 주소는 LAN 어댑터의 ROM에서 읽어오나, LAN 어댑터가 여러 개 일경우 하나를 선택해야 한다.
수신용 MAC 주소는 패킷을 최종 건네줄 대상을 아직 파악하지 못했기 때문에 IP경로표에서 찾은 ‘Gateway’ 항목에 기록되어 있는 IP주소의 기기가 패킷을 건네줄 상대가 된다.
ARP로 수신처 라우터의 MAC 주소를 조사한다
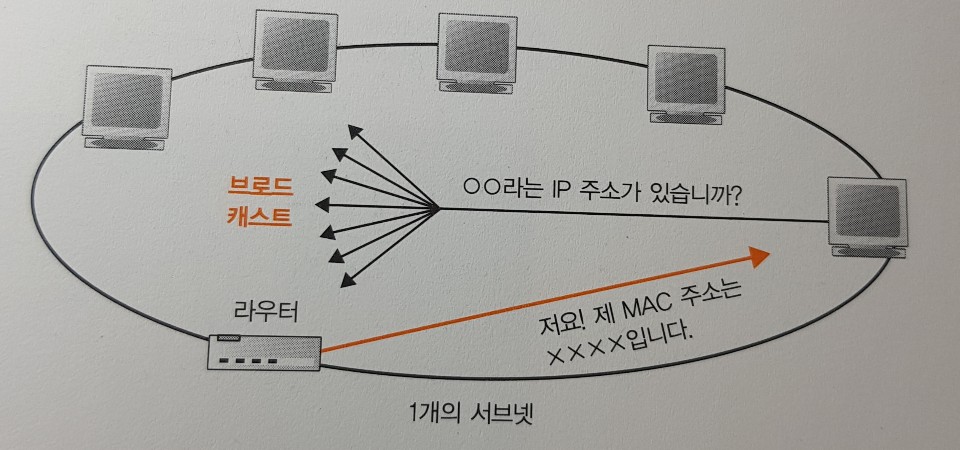
ARP(Address Resolution Protocol
이더넷에는 연결되어 있는 전원에게 패킷을 전달하는 브로드캐스트라는 구조가 있다. 이 구조를 이용하여 해당 IP를 갖고 있는 서브넷을 찾아낸다(모두에게 질의하고 해당 대상만 응답한다). 패킷을 보낼 때마다 이 동작을 하면 ARP 패킷이 불어나기 때문에 한 번 조사한 결과는 ARP 캐시라는 메모리 영역에 보존하여 다시 이용한다. 즉, 패킷을 송신할 때 우선 ARP 캐시를 조사하여 거기에 상대의 MAC 주소가 존재하면 ARP를 조회하지 않고 ARP 캐시에 저장된 값을 사용하는 것이다. IP 주소를 설정하여 고쳐진 경우 등 ARP 캐시에 저장된 값과 실제 데이터와 일치 않을 수 있기 때문에 일정 시간이 지나면 삭제된다.
MAC 헤더를 IP 헤더 앞에 붙이면 패킷이 완성된다. 이렇게 패킷을 만들기까지가 IP 담당 부분의 역활이다. LAN 어댑터는 완성된 패킷을 송신하기만 하면 된다.
ref 성공과 실패를 결정하는 1% 네트워크 원리
16 Dec 2019
|
Network
TCP의 통신 과정 (2)
프로토콜 스택은 받은 데이터를 곧바로 송신하는 것이 아니라 일단 자체의 내부에 있는 송신용 버퍼용 메모리 영역에
저장하고 특정 요소에 따라 송신을 결정한다.
프로토콜 스택이 송신하기 위한 요소
- MTU
- 타이밍
MTU
- 프로토콜 스택은 MTU라는 매개변수를 바탕으로 송신을 결정한다.
MTU는 한 패킷으로 운반할 수 있는 디지털 데이터의 최대 길이로, 이더넷에서는 보통 1,500 바이트가 된다.
- MTU에는 패킷의 맨 앞부분에 헤더가 포함되어 있으므로 여기부터 헤더를 제외한 것이 하나의 패킷으로 운반할 수 있는
최대 길이가 되고, 이 것을 MSS라고 합니다.
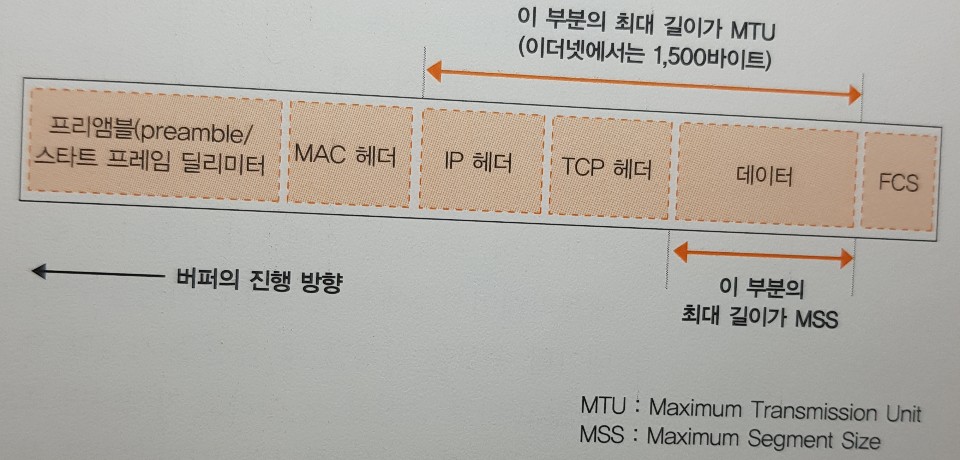
타이밍
데이터가 클 때는 분할해서 보낸다
-
HTTP 리퀘스트 메시지 보통 길지 않으므로 한 개의 패킷에 들어가지만, 폼을 사용하여 긴 데이터를 보낼 경우 등
한 개의 패킷에 들어가지 않을 만큼 긴 것도 있다.
이 경우 송신 버퍼에 들어있는 데이터를 맨 앞부터 차례대로 MSS 크기에 맞게 분할하고
분할한 조각을 한 개씩 패킷에 넣어 송신한다.
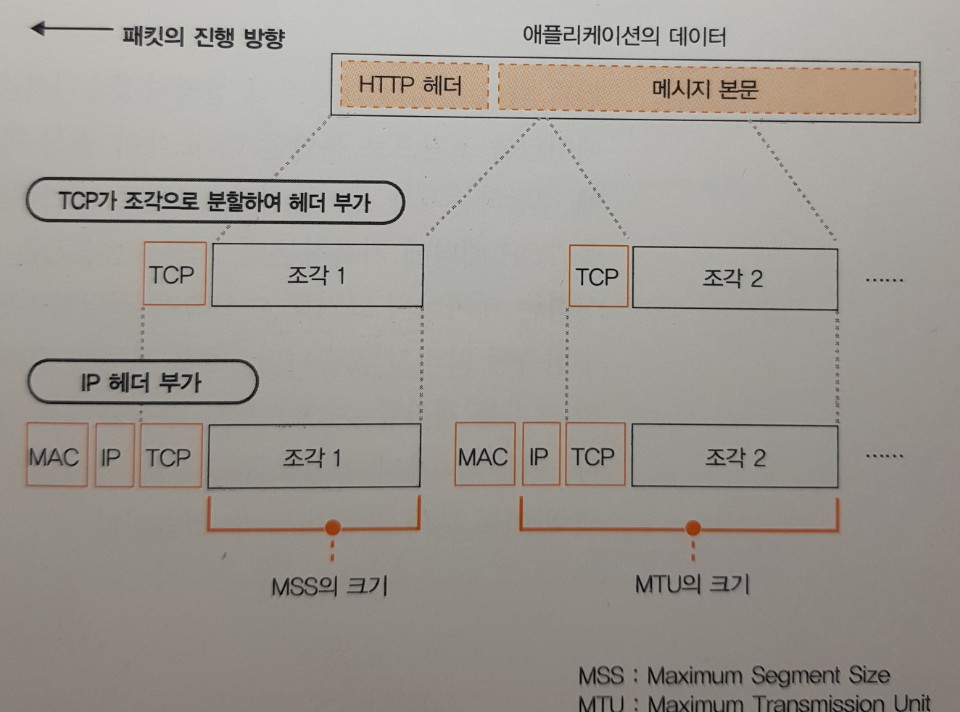
데이터 송∙수신 과정
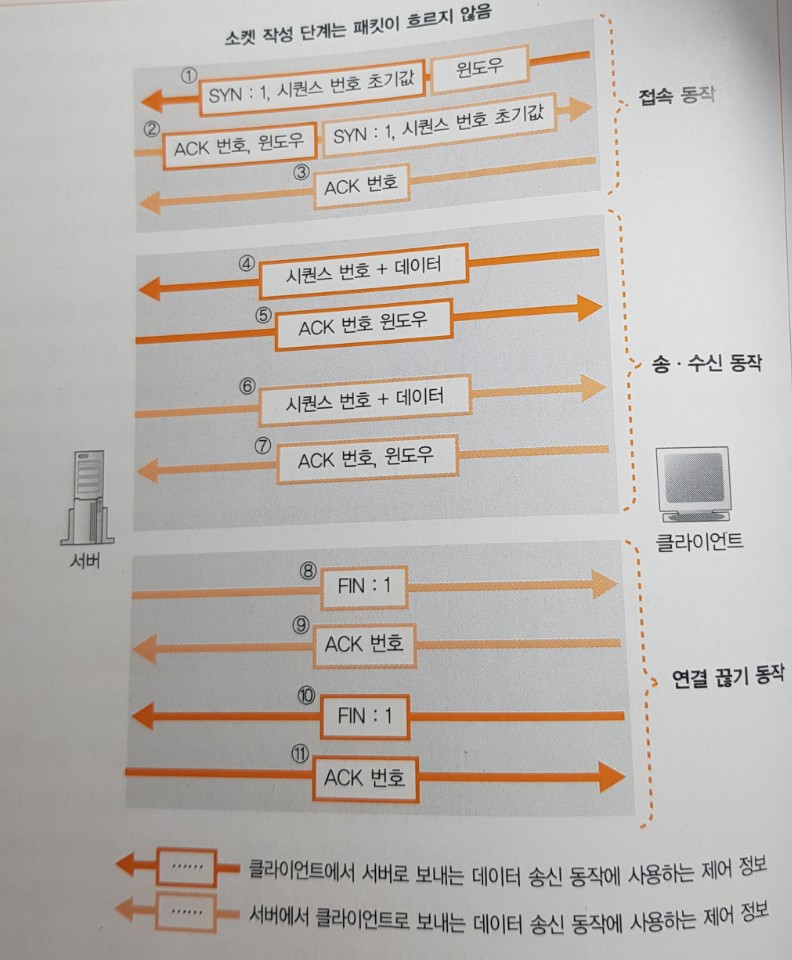
- 서버측에서 애플리케이션이 동작하기 시작할 때 소켓을 만들고 접속 대기상태로 존재한다.
- 클라이언트측에서 소켓을 만든다.
-
그림 ① : SYN을 1로 만들고 시퀀스번호 초기값[1], 윈도우[2]로 TCP 헤더를 만들어 서버에 보낸다.
- 그림 ② : 이 것이 서버에 도착하면 서버에서 SYN을 1로 만들고 시퀀스 번호와 윈도우, ACK 번호[3]로 TCP 헤더를 만들어 클라이언트의 요청에 응답한다.
-
그림 ③ : 이 것이 클라이언트에 도착하면 TCP 헤더를 받은 것을 나타내는 ACK 번호를 기록한 TCP 헤더를
클라이언트가 서버에 보낸다. 이것으로 접속 동작은 끝나고 데이터 송∙수신 단계에 들어간다.
-
그림 ④ : 웹의 경우 클라이언트에서 서버에 리퀘스트 메시지를 보내는 것부터 시작한다.
TCP는 이것을 적당한 크기의 조각으로 분할하고 TCP 헤더를 맨 앞에 부가하여 서버에 보낸다.
-
그림 ⑤ : TCP 헤더에 송신 데이터가 몇 번째 바이트부터 시작되는지를 나타내는 시퀀스 번호가 기록되어 있을 것(그림④)이고, 이 것이 서버에 도착하면 서버는 ACK 번호를 클아이언트에 반송한다.
최초의 데이터 조각인 경우 서버는 데이터를 받기만 하지만, 데이터 송∙수신이 진행되면 애플리케이션에 데이터를 건네주어수신 버퍼에 빈 영역이 생기는 장면이 나오는데, 이때 윈도우의 값도 기록하여 클라이언트에 통지한다.
- 서버가 응답 메시지 보내기를 완료하면 데이터 송∙수신 동작이 끝나므로 연결 끊기 동작에 들어간다.
웹의 경우 서버에서 연결 끊기 동작에 들어간다.
그림 ⑧ : 서버에서 먼저 FIN을 1로 만든 TCP 헤더를 클라이언트에 보낸다.
-
그림 ⑨ : 이 것을 받았음을 나타내는 ACK 번호의 TCP 헤더가 클라이언트에서 서버로 돌아온다.
-
그림 ⑩ : 이후 클라이언트가 FIN을 1로 만든 TCP 헤더를 서버에 보낸다.
-
그림 ⑪ : 서버에 받았다는 의미의 ACK 번호의 TCP 헤더를 클라이언트에 반환하고 소켓이 말소된다.
TCP는 통신 과정에서 ACK 번호가 돌아오지 않으면 패킷을 다시 보낸다.
다른 곳(LAN 어댑터,라우터, 버퍼 등)에서 오류조치할 필요가 없다.
[1] 시퀀스 번호
-
시퀀스 번호는 데이터를 조각으로 분할하여 송신할 때 몇번 째 바이트에 해당하는지를 나타내는 것으로써
보통 1부터 시작하지 않고 난수를 바탕으로 산출한 초기값으로 시작한다.
항상 1부터 시작한다면 악의적인 공격을 할 우려가 있기 때문이다.
[2] 윈도우
- 송신 측에 수신 가능한 데이터 양을 통지하고, 수신측은 이 양을 초과하지 않도록 송신 동작을 진행하는데
수신가능한 양을 윈도우라 한다.
[3]ACK 번호
- 수신자가 예상하는 다음 시퀀스 번호이다. 이것은 모든 선행하는 바이트들(존재할 경우)에 대한 수신에 대한 확인응답이 된다.
- 한쪽이 보낸 최초의
ACK는 반대쪽의 초기 시퀀스 번호 자체에 대한 확인응답이 되며, 데이터에 대한 응답은 포함되지 않는다.
ref 성공과 실패를 결정하는 1% 네트워크 원리
ref wiki

 jayyhkwon의 개발공부로그
jayyhkwon의 개발공부로그