12 Apr 2020
|
layout: post
title: " 20200412_TIL "
category: TIL (Today I Learned)
tags: [TIL]
comments: true
2020_04_12
CQRS (Command and Query Responsibility Segregation)
- 데이터에 대한 조작 Create, Insert, Delete, Update와 조회 Select를 구분한다
MVCC (Multi Version Concurrency Control) 다중버전 동시성 제어
과거 DBMS의 경우 lock 메커니즘을 이용하여 동시성을 제어하였다.
쓰기의 경우 exclusive-lock을 사용하여 쓰기 작업을 하는 트랜잭션이 끝나기 전까지 다른 트랜잭션이 접근 불가능 하다
반면, 읽기의 경우 shard-lock을 사용하여 해당 트랜잭션이 끝나기 전에도 다른 트랜잭션이 접근 가능하다.
lock 메커니즘을 사용할 경우 교착상태에 빠질 수 있으며, 속도적인 측면에서 불리한 점이 있어 MVCC 메커니즘이 보편화되었다.
데이터를 버저닝하여 lock없이 독립적으로 트랜잭션을 완료할 수 있다 (속도 향상, 교착상태 발생x)
구체적인 예를 보자면
- A가 1번째 row의 x 컬럼 값을 읽었다. 값을 10이라 가정하자.
- B도 1번째 row의 x 컬럼 값을 읽었다. 1과 같은 값이다.
- A가 10-> 15로 값을 변경하고 트랜잭션을 커밋하였다.
- B가 10-> 20으로 값을 변경하고 트랜잭션을 커밋했다.
- DB 입장에서 동일한 데이터에 대해 A가 먼저 커밋한 것을 알고 있으니 B가 커밋을 시도한 시점에 에러 메시지를 발생시키고 15인 값을 새로 읽은 다음 충돌 해결을 B에게 위임한다 (git의 conflict와 동일한 원리)
MVCC JDBC option is unsupported in 1.4.198 and 1.4.199
https://github.com/h2database/h2database/issues/2198
SpringBoot 2.2 부터는 JUnit 5가 default
https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.2-Release-Notes</a>
junit의 vintage-engine을 사용할 경우 기존 junit 4 기반의 테스트 클래스들을 사용할 수 있다.
build.gradle에서 exclude 되어 있어 주석 처리하니 해결됨.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-devtools'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
// exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
ref. h2
ref. wiki
ref. 데이터넷
ref. blog
25 Mar 2020
|
Java
URL과 URI
URI (Uniform Resource Identifier)
- 추상적이거나 또는 물리적인 자원을 완전히 완전히 구분할 수 있는 문자열
URL (Uniform Resource Locator)
- URI의 부분집합.
- URL + 자원이 어디에 위치하는 지 나타낸다
모든 URL은 URI이지만 역은 성립하지 않는다
예시
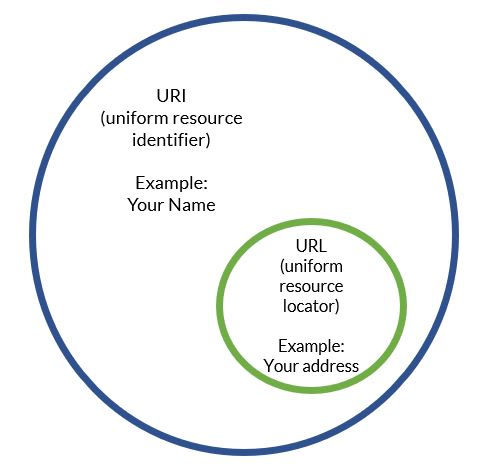
이름은 URI이지만, URL은 아니다. 이름을 안다고 해서 어디에 위치하는지 알 수 없기 때문이다.
반면 주소는 URI이면서 URL이다. 주소를 알면 내가 누군지 알 수 있으며, 어디에 위치하는지 또한 알 수 있기 때문이다
Syntax
모든 URI는 다음 형태를 가진다.
scheme: [//authority] [/path] [?query] [#fragment]
- scheme
- URL의 경우 이것은 자원에 접근하기 위한 프로토콜에 해당한다
- authority
- authority = [ userinfo “@” ] host [ “:” port ]
- 유저 권한정보(옵션), 호스트(필수), 포트(옵션)으로 구성된다
- path
- scheme와 authority에서 자원을 구별하는 역활을 한다
- query
- path 뒤에 오는 추가적인 정보로 자원을 구별하는 역활을 한다.
- fragment
URI, URL class in JAVA
URI 클래스만이 모든 syntax 구성요소에 대한 생성자를 가진다
@Test
public void whenCreatingURIs_thenSameInfo() throws Exception {
URI firstURI = new URI(
"somescheme://theuser:thepassword@someauthority:80"
+ "/some/path?thequery#somefragment");
URI secondURI = new URI(
"somescheme", "theuser:thepassword", "someuthority", 80,
"/some/path", "thequery", "somefragment");
assertEquals(firstURI.getScheme(), secondURI.getScheme());
assertEquals(firstURI.getPath(), secondURI.getPath());
}
@Test
public void whenCreatingURLs_thenSameInfo() throws Exception {
URL firstURL = new URL(
"http://theuser:thepassword@somehost:80"
+ "/path/to/file?thequery#somefragment");
URL secondURL = new URL("http", "somehost", 80, "/path/to/file");
assertEquals(firstURL.getHost(), secondURL.getHost());
assertEquals(firstURL.getPath(), secondURL.getPath());
}
ref. RFC 3986
ref. baeldung
25 Mar 2020
|
Etc
Base 64 인코딩이란?
인코딩
Base64 인코딩에 대해 알아보기전에 먼저 인코딩이란게 무엇인지 간략하게 알아보자. 인코딩은 정보의 형태나 형식을 표준화,
보안, 처리 속도 향상, 저장 공간 절약 등을 위해서 다른 형태나 형식으로 변환하는 처리 혹은 그 처리 방식을 말한다.
동영상이나 이미지영역에서도 많이 사용되는 용어지만 우리는 Binary Data를 Text로 바꿔주는 Base64 인코딩에 대해서
알아봐야 하기 때문에 이하는 생략한다.
Base64 인코딩
Base64란 Binary Data를 Text로 바꾸는 Encoding(binary-to-text encoding schemes)의 하나로써 Binary Data를 Character set에 영향을 받지 않는 공통 ASCII 영역의 문자로만 이루어진 문자열로 바꾸는 인코딩이다.
Base64 글자를 그대로 직역하면 64진법이라는 뜻이다. 64진법은 컴퓨터한테 특별한데 그 이유는 2의 제곱 수이며 2의 제곱 수에 기반한 진법 중 화면에 표시되는 ASCII 문자들로 표시할 수 있는 가장 큰 진법이기 때문이다. (ASCII에는 제어문자가 다수 포함되어 있기 때문에 화면에 표시되는 ASCII 문자는 128개가 되지 않는다)
핵심은 Base64 인코딩은 Binary Data를 Text로 변경하는 인코딩이다.
변경하는 방식은 Binary Data를 6bit 씩 자른 뒤 6 bit에 해당하는 문자를 아래 Base64 색인표에서 찾아 치환한다.
(실제로는 Padding을 더해주는 과정이 추가된다)
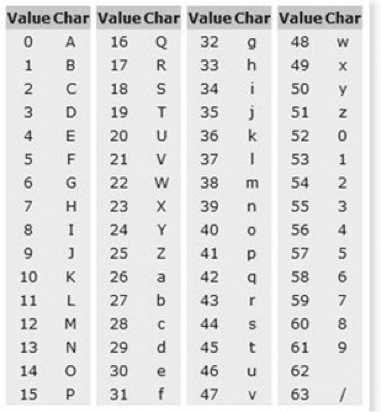
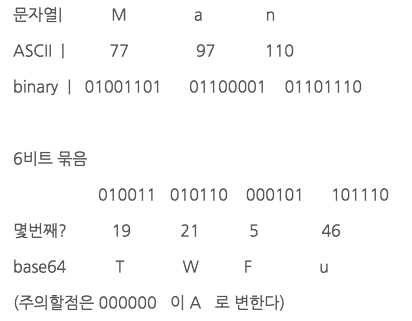
기본적인 원리는 간단하다. 문자열 -> ASCII -> binary -> 6bit cut -> base64_encode
그런데 한 가지 문제가 있다. 모든 문자열이 3개(24bit)씩 남김없이 끊어지진 않는다는 것이다.
그래서 padding을 하게 되는데 padding의 뜻 그대로 ‘불필요하게 넣은 군더더기’라고 생각하면 된다.
만약 3개씩 끊어지지않고 빈자리가 생긴다면 인코딩 후 패딩문자인 =가 그 빈자리만큼 들어가게 된다.
즉 Many -> 77 97 110 121 -> 01001101 01100001 01101110 01111001
-> 010011 010110 000101 101110 011110 010000 (남은 비트 뒤에 ‘0’을 채워 6비트 만듬)
-> TWFueQ가 되고, 처음에 Man y– 이므로 2개의 빈공간이 있음을 알려주기 위해 패딩문자를 추가
-> TWFueQ== 가 base64 인코딩의 최종 결과물이 된다
ref. wiki
ref. blog

 jayyhkwon의 개발공부로그
jayyhkwon의 개발공부로그