
 jayyhkwon의 개발공부로그
jayyhkwon의 개발공부로그
Singleton 패턴
08 Oct 2019 | DesignPatternSingleton 패턴
- 생성자가 여러 차례 호출되더라도 실제로 생성되는 객체는 하나이고 최초 생성 이후에 호출된 생성자는 최초의 생성자가 생성한 객체를 리턴한다.
- 주로 공통된 객체를 여러개 생성해서 사용하는 DBCP(DataBase Connection Pool)와 같은 상황에서 많이 사용된다.
자바에서 싱글턴 패턴을 구현할 때 고려해야 할 사항은 크게 2가지다. - 1. thread-safe. - 2. 메모리 낭비.
이를 위해 synchronized(동기화)와 lazy loading 기법을 사용하기도 하지만 개발자가 작성하는 코드에는 성능 및 정확성으로 인한 문제가 발생할 여지가 있다. (Double Checked Locking, lazy initialation 등등)
어떻게 하면 이러한 문제 발생의 여지를 없앨 수 있을까? 바로 클래스 로더와 lazy initialation을 이용하는 것이다.
public class Something {
private Something(){
System.out.println("Something Constructor is called");
}
static{
System.out.println("Something static load");
}
private static class LazyHolder {
public static final Something INSTANCE = new Something();
static {
System.out.println("Holder static load");
}
}
public static Something getInstance(){
return LazyHolder.INSTANCE;
}
public static void main(String[] args) {
System.out.println("main() started");
Something a = Something.getInstance();
}
}
--- 실행결과 ---
Something static load
main() started
Something Constructor is called
Holder static load
--------------
클래스 로더는 크게 2가지 방식으로 클래스를 로딩한다.
- 1) 런타임 로딩 : 특정 클래스의 코드를 실행할 떄 클래스를 로딩한다.
- 2) 로드 타임 로딩 : 런타임 로딩에 의해서 클래스(A)가 로딩 될때, 해당 클래스(A) 내부에서 참조(사용)하는 클래스(B,C...)가 있다면 그 클래스도 로드하는 방법
Something 클래스로 예를 들어 설명해 보자면
- 해당 코드를 실행하면 main() 메서드가 존재하는 Something 클래스를 로딩한다. (런타임 로딩)
- main() 메서드가 실행된다.
- Something.getInstance() 메서드 호출에 의해 LazyHolder 클래스가 로딩된다. (런타임 로딩)
- Something() 생성자가 호출된다. (lazy loading)
- LazyHolder의 static 블록이 실행된다.
클래스가 로딩되는 시점은 ‘thread-safe’ 함을 JVM이 보장해주며 사용시점에 클래스가 로딩되므로 미리 생성하여 발생하는 메모리 낭비도 없다는 장점이 있어 Singleton 구현 시 가장 많이 사용되는 기법 중 하나이다.
해당 구현 기법은 ‘Bill Pugh Solution’ 이며 Enum을 이용한 싱글턴 구현 기법 또한 많이 사용된다고 하니 궁금한 사람은 찾아보면 좋을 것 같다.
ref. https://blog.seotory.com/post/2016/03/java-singleton-pattern
ref. https://javacan.tistory.com/entry/1
ref. https://jeong-pro.tistory.com/86
ref. https://limkydev.tistory.com/67
ref. https://ko.wikipedia.org/wiki/%EC%8B%B1%EA%B8%80%ED%84%B4_%ED%8C%A8%ED%84%B4
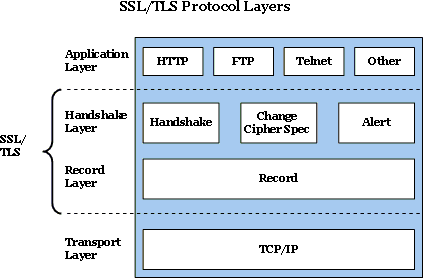
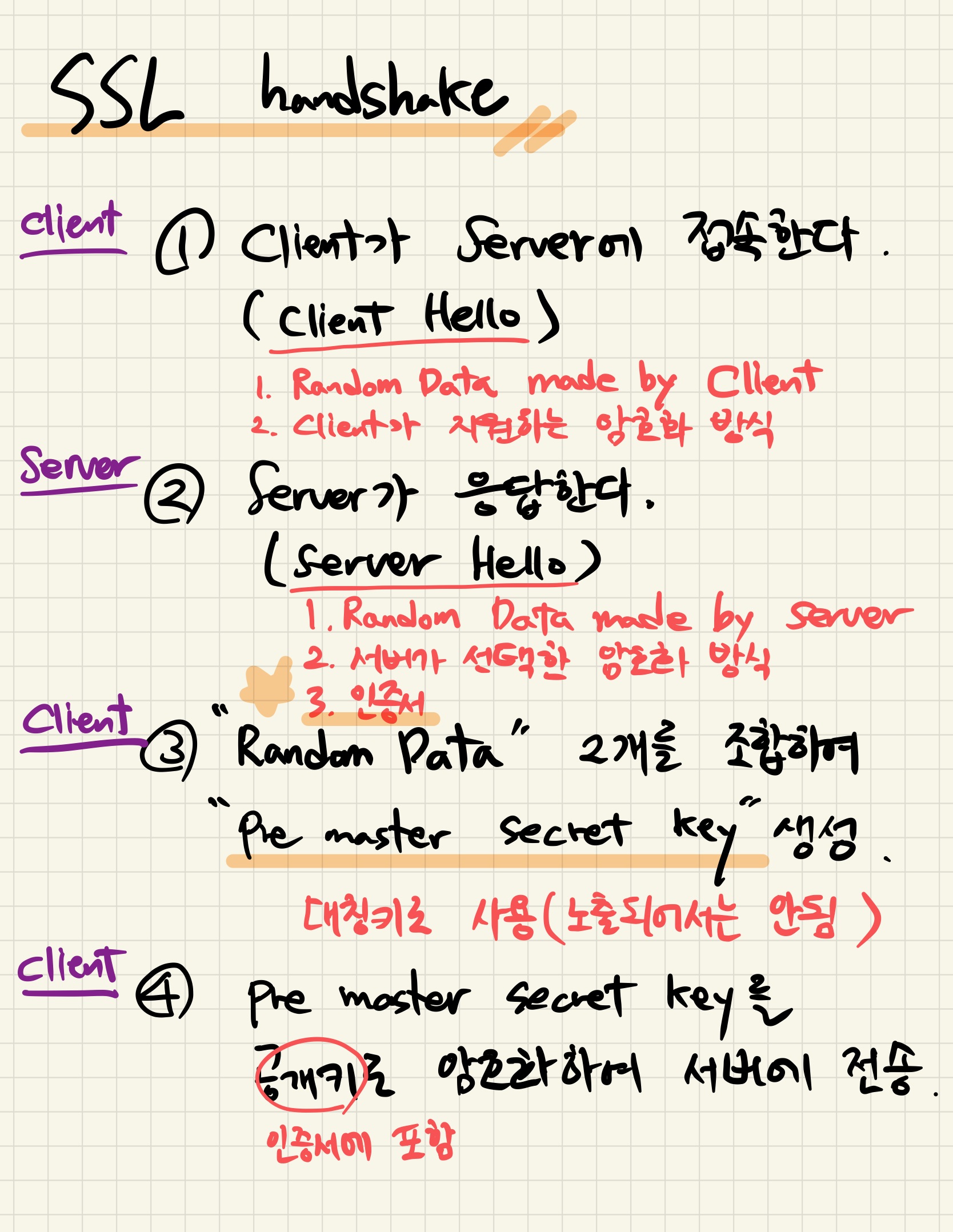

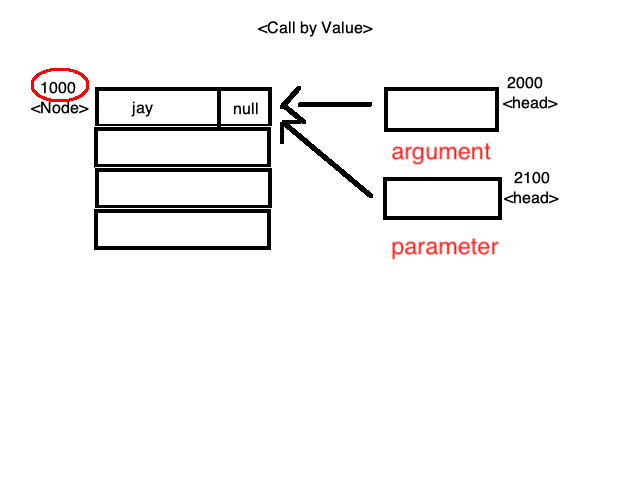 < 그림 1 >
< 그림 1 >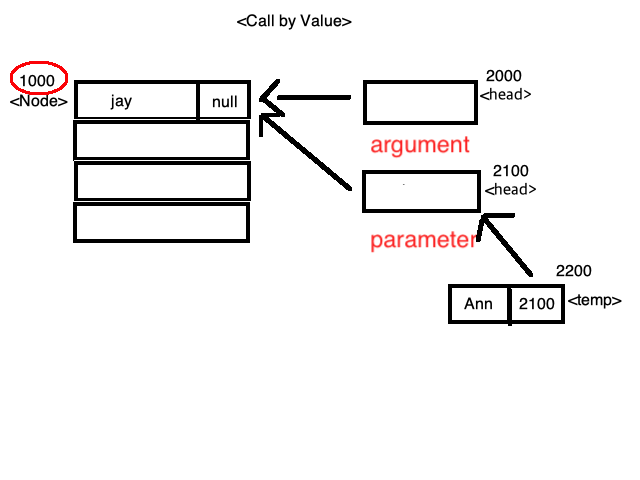 < 그림 2 >
< 그림 2 >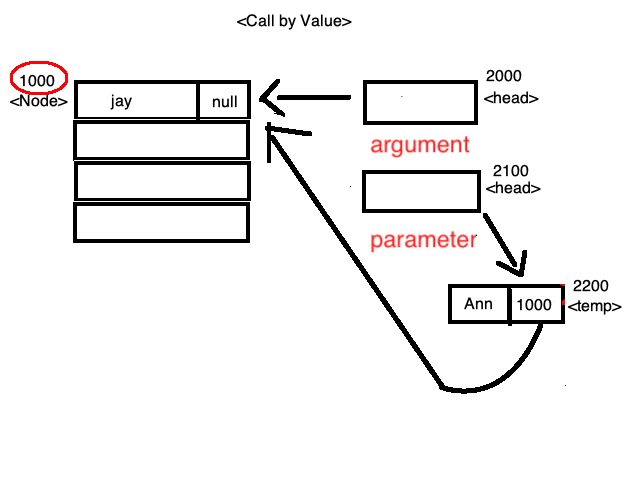 < 그림 3 >
< 그림 3 >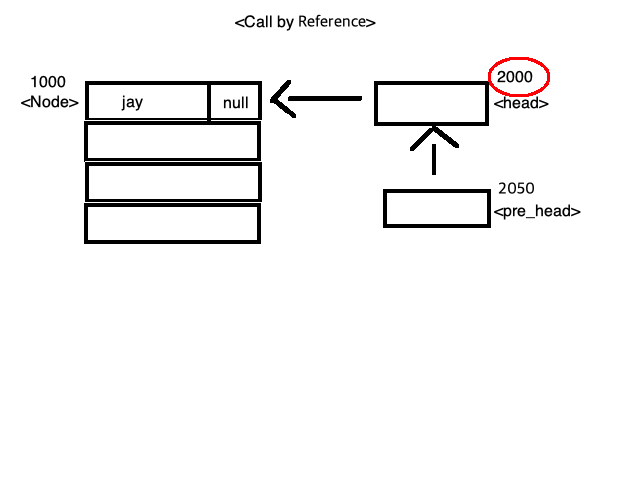 < 그림 4 >
< 그림 4 >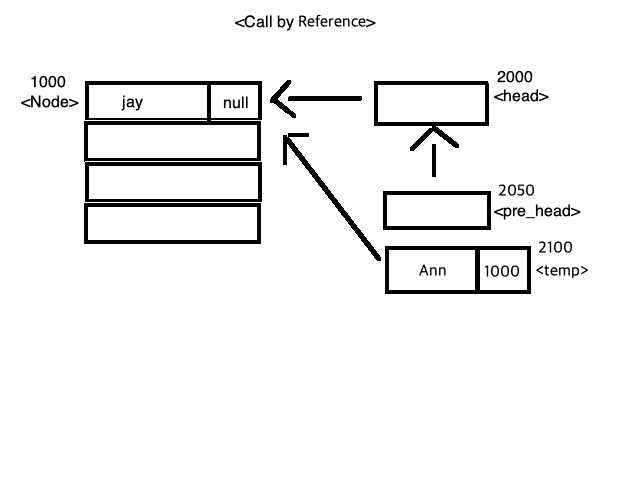 < 그림 5 >
< 그림 5 >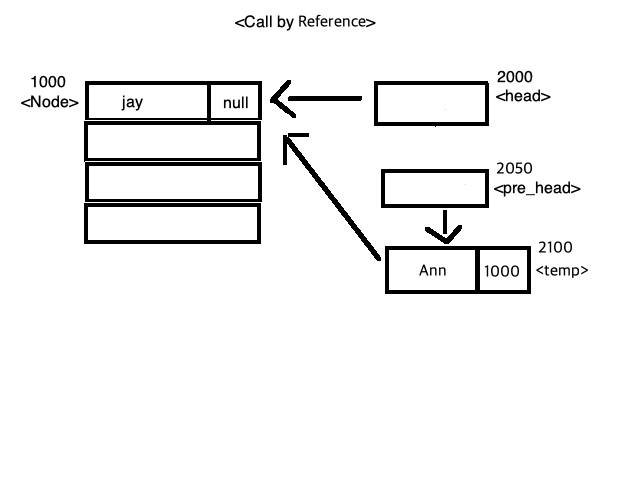 < 그림 6 >
< 그림 6 >