31 Oct 2019
|
Java
ArrayList 시간복잡도
ArrayList의 메서드 get(), add(), remove()의 시간복잡도를 알아보자.
목차
- get(int index)
- add()
- add(E element)
- add(int index, E element)
- remove(int index)
1. get(int index)
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
ArrayList는 Obect[]로 구현되어 있으므로 랜덤엑세스가 가능하다.
따라서 시간복잡도 : O(1)
2. add()
add()의 경우 배열의 마지막에 element를 추가하는 add(E element) 메서드와
특정 인덱스에 element를 추가하는 add(int index, E element) 메서드로 나뉜다.
2-1. add(int index)
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
메서드는 크게 두 부분으로 나뉜다.
- 배열의 크기를 확인하는 부분 -> “ensureCapacityInternal(size + 1)”
- 배열의 lastIndex에 element를 추가하는 부분 -> “elementData[size++] = e;”
배열의 크기를 확인하는 부분을 까보면
size >= length일 경우에 grow() 메서드가 실행됨을 알 수 있다.
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
// size >= length이므로 grow() 메서드 호출
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
grow() 메서드는 배열을 복사하므로 이 작업의 시간복잡도는 배열의 원소의 갯수 n에 비례한다.
따라서 배열의 크기를 확인하는 부분의 시간복잡도는 O(n)이다.
배열에 lastIndex에 element를 추가하는 부분의 시간복잡도는 get()과 마찬가지로 O(1)이다.
즉 add(E element)는 시간복잡도 O(n)과 O(1)이 공존하는데
이를 계산하기 위해 분할상환분석을 사용한다.
분할상관분석에 의해
배열의 크기를 증가하는 작업(시간복잡도가 O(n))보다는 배열의 lastIndex에 element를 추가하는 작업이 훨씬 많으므로 이를 평균내면 O(1)의 시간복잡도를 가진다.
2-2. add(int index, E element)
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
해당 index의 오른쪽에 존재하는 모든 element들의 index를 옮겨야 하므로
시간복잡도는 배열의 원소의 갯수 n에 비례한다.
따라서 시간복잡도는 O(n)이다.
3. remove(int index)
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
해당 index의 오른쪽에 존재하는 모든 element들의 index를 옮겨야 하므로
시간복잡도는 배열의 원소의 갯수 n에 비례한다.
따라서 시간복잡도는 O(n)이다.
ref. https://stackoverflow.com/questions/45220908/why-arraylist-add-and-addint-index-e-complexity-is-amortized-constant-time
ref. https://ko.wikipedia.org/wiki/%EB%B6%84%ED%95%A0%EC%83%81%ED%99%98%EB%B6%84%EC%84%9D
28 Oct 2019
|
Algorithm
목차
1. 정의
2. 재귀적인 접근
3. Recursion vs Iteration
4. 재귀 알고리즘 설계시 주의할 점
- base case
- 암시적 매개변수를 명시적 매개변수로 바꾸어라.
1. 정의
public static void main(String[] args){
recursive();
}
public static void recursive(){
System.out.println("recursive");
recursive(); // 자기 자신을 호출
}
2. 재귀적인 접근
- 길이가 n인 문자열이 있다고 하자 .
이 문자열의 길이를 구할 때 for문으로 구한다고 하면 이렇게 구할 수 있을 것이다.
public static int length(String str){
if(str == null || str.equals(""))
return 0;
int length = 0;
for(int i=0; i<str.length(); i++) {
length++;
}
return length;
}
이번엔 for문 없이 재귀적으로 문자열의 길이를 구해보자.
public static int lengthByRecursive(String str){
if(str == null || str.equals(""))
return 0;
return 1+length(str.substring(1));
}
3. Recursion vs Iteration
- 모든 재귀함수(Recursion)는 반복문(iteration)으로 변경가능하다.
- 그 역도 성립한다. 즉, 모든 반복문은 Recursion으로 표현 가능하다.
- 재귀함수는 복잡한 알고리즘을 단순하고 알기쉽게 표현하는 것을 가능하게 한다.
- 하지만 함수 호출에 따른 오버헤드가 있다(매개변수 전달, 액티베이션 프레임생성 등)
4. 재귀 알고리즘 설계시 주의할 점
- base case
- 1의 예제 실행 시 종료되지 않고 무한 호출 된다.
- 이를 막기 위해 적어도 하나의 base case, 즉 순환되지 않고 종료되는 case가 있어야 함.
- 모든 case는 결국 base case로 수렴해야 한다.
public static void main(String[] args){
recursive(5); // 5번 호출
}
public static void recursive(int n){
// base case
if(n <= 0)
return;
System.out.println("recursive");
recursive(n-1); // 자기 자신을 호출
}
- 암시적 매개변수를 명시적 매개변수로 바꾸어라.
public int search(int[] data, int n, int target){
for(int i=0; i<n; i++){
if(data[i]==target)
return i;
}
return -1;
}
이 함수의 미션은 data[0]에서 data[n-1] 사이에서 target을 검색하는 것이다.
하지만 검색 구간의 시작 인덱스 0은 보통 생략한다. 즉 암시적 매개변수다.
이렇게 암시적 매개변수로 함수(메서드)를 만들게 되면 재귀함수를 호출할 수 없으므로
아래와 같이 명시적으로 매개변수를 수정하여야 한다.
// 앞에서부터 순차적으로 target을 찾는 재귀함수
public int search(int[] data, int begin, int end, int target){
if(begin>end)
return -1;
else if(target == data[begin]){
return begin;
}
else
return search(data,begin+1,end,target);
}
25 Oct 2019
|
Java
다운캐스팅 시 컴파일 에러가 발생하지 않는 이유
상위 클래스에서 하위 클래스로 캐스팅 하는 것.
public static void main(String[] args) {
Object obj = new Object();
String s = (String) obj; // down-casting
Object o = (Object) new String("string"); // up-casting
}
본격적인 설명에 들어가기 전에 클래스 다이어그램을 보자.
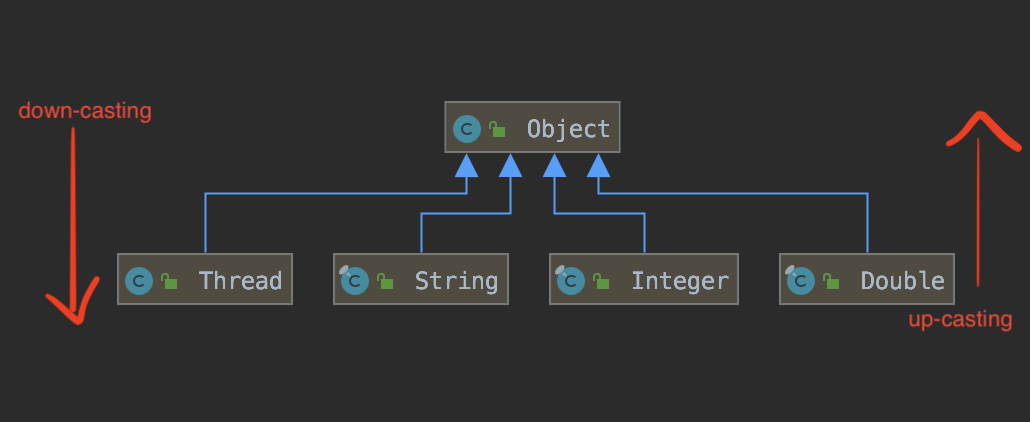
알다시피 Object 클래스는 자바에 존재하는 모든 객체들의 최상위 클래스다.
따라서 Object가 아닌 객체 -> Object(업 캐스팅) : true
Object -> Object가 아닌 객체(다운 캐스팅) : ?
Object를 확장한 객체는 Object 객체가 가진 데이터(프로퍼티,메서드)보다 많은 걸 내포할 가능성이 있기 때문이다.
위 코드는 컴파일 시점에서는 문제가 없지만
코드를 실행하게 되면 Exception in thread “main” java.lang.ClassCastException: java.lang.Object cannot be cast to java.lang.String runtime Exception이 발생한다.
미리 컴파일시점에 이런 문제를 발견하면 좋을텐데 왜 컴파일러는 이런 문제를 발견하지 못하는 걸까?
바로 객체의 동적 할당과 다형성 때문이다.
public static void main(String[] args) {
Object obj = new Object();
String s = (String) obj; // down-casting (throw ClassCastException)
Object strObj = new String("str"); // type is Object, but Concrete class is String.
String str = (String) strObj; // down-casting (valid)
}
자바는 new 연산자를 통해 객체를 동적 할당(런타임 시점에 할당) 하므로
컴파일 시점에서는 변수 obj, strObj는 Object 타입이라는 것만 알 수 있고 실제 할당되는 객체는 알 수 없다.
// 컴파일 시점(실제 할당되는 객체는 알 수 없다)
Object obj = null;
String s = (String) obj;
Object strObj = null;
String str = (String) strObj;
-> String 타입은 Object 타입이므로 (다형성) 컴파일러 입장에서 obj와 strObj의 구현 클래스를 모르는 상황에서 캐스팅을 막을 수 없다.
// 런타임 시점(실제 객체가 할당된다)
Object obj = new Object();
String s = (String) obj; // down-casting (throw ClassCastException)
Object strObj = new String("str");
String str = (String) strObj; // down-casting (valid)
-> 1. obj : 구현 클래스(Object) -> String으로 캐스팅 하였으므로 ClassCastException이 발생.
2. strObj : 구현 클래스(String) -> String으로 캐스팅 하였으므로 캐스팅 성공.
자바 컬렉션 프레임워크(JCF)의 사용이 보편화된 이유 중에 하나도
JCF가 탄생하기 전에 Object 타입을 이용한 컨테이너를 만들어 사용할 때 발생하는
- element를 꺼낼때마다 일일이 캐스팅 해야 하는 번거로움
- 다운 캐스팅 문제발생 가능성이 존재 한다고 알고 있었는데
이번 기회를 통해 확실히 JCF의 소중함을 알게 되었다.
ref. https://stackoverflow.com/questions/14180861/downcasting-upcasting-error-at-compile-time-runtime
ref. https://www.geeksforgeeks.org/new-operator-java/
ref. https://www.geeksforgeeks.org/g-fact-46/
ref. https://docs.oracle.com/cd/E13150_01/jrockit_jvm/jrockit/geninfo/diagnos/garbage_collect.html#wp1085990
25 Oct 2019
|
Java
List.add()가 항상 return true인 이유
List.add()의 return type이 boolean인데
List 인터페이스의 구현 클래스인 ArrayList와 LinkedList의 return 값이 항상 true인 게 의문이 들었다.
ArrayList.java
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
LinkedList.java
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
그래서 List의 superType인 Collection을 찾아봤더니
Ensures that this collection contains the specified element (optional operation). Returns true if this collection changed as a result of the call. (Returns false if this collection does not permit duplicates and already contains the specified element.) -java doc-
Collection에 중복이 허용되지 않거나, 특정 element가 존재하는 경우 return false라고 한다.
List 타입은 중복을 허용하므로 ArrayList와 LinkedList가 항상 true를 리턴 할 수 밖에 없구나..
ref. https://docs.oracle.com/javase/7/docs/api/
23 Oct 2019
|
Java
Java 8 in Action(Chapter 3)
이 장의 내용
- 람다란 무엇인가?
- 어디에, 어떻게 람다를 사용하는가?
- 실행 어라운드 패턴
- 함수형 인터페이스, 형식 추론
- 메서드 레퍼런스
-
람다 만들기
- 람다란 무엇인가?
- 람다 표현식은 메서드로 전달할 수 있는 익명 함수를 단순화한 것이라고 할 수 있다.
람다 표현식에는 이름은 없지만
1) 파라미터 리스트
2) 바디
3) 리턴 타입
4) 발생할 수 있는 예외 리스트는 가질 수 있다.
// 람다 표현식 기본 문법
1. (parameters) -> expression
2. (parameters) -> {statements;}
// 람다 표현식 1
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight())
-------------------- ----------------------------------------
파라미터 리스트 바디(return이 함축되어 있으므로 리턴 타입은 int)
// 람다 표현식 2
(int x, int y) -> { System.out.println("Result:");
System.out.println(x+y); }
-------------- ---------------------------------------------
파라미터 리스트 바디(리턴 타입은 void)
// 람다 표현식 3
() -> 42
------- ----
파라미터 x 리턴 타입은 int
람다의 특징
1) 익명
- 보통의 메서드와 달리 이름이 없으므로 익명이라 표현한다.
2) 함수
- 람다는 메서드처럼 특정 클래스에 종속되지 않으므로 함수라고 부른다.
3) 전달
- 람다 표현식을 메서드 인수로 전달하거나 변수로 저장할 수 있다.
4) 간결성
- 익명 클래스처럼 많은 자질구레한 코드를 구현할 필요가 없다.
- 어디에, 어떻게 람다를 사용하는가?
ref. http://www.hanbit.co.kr/store/books/look.php?p_code=B1999551123

 jayyhkwon의 개발공부로그
jayyhkwon의 개발공부로그